DeepSpeed Compression: A composable library for extreme
$ 9.00 · 4.7 (652) · In stock

Large-scale models are revolutionizing deep learning and AI research, driving major improvements in language understanding, generating creative texts, multi-lingual translation and many more. But despite their remarkable capabilities, the models’ large size creates latency and cost constraints that hinder the deployment of applications on top of them. In particular, increased inference time and memory consumption […]
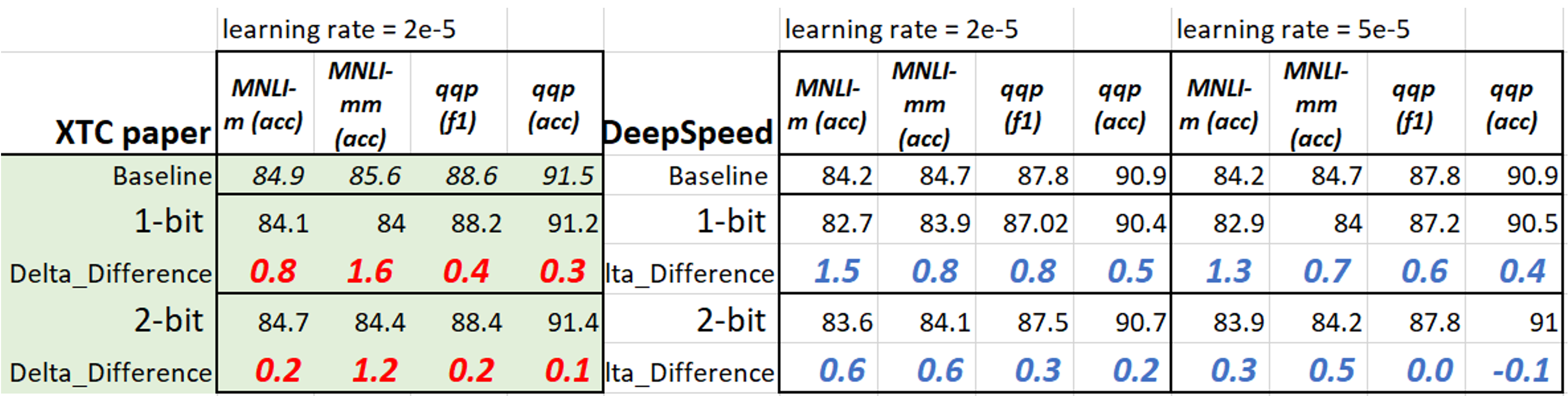
DeepSpeed Model Compression Library - DeepSpeed

ZeRO-2 & DeepSpeed: Shattering barriers of deep learning speed & scale - Microsoft Research
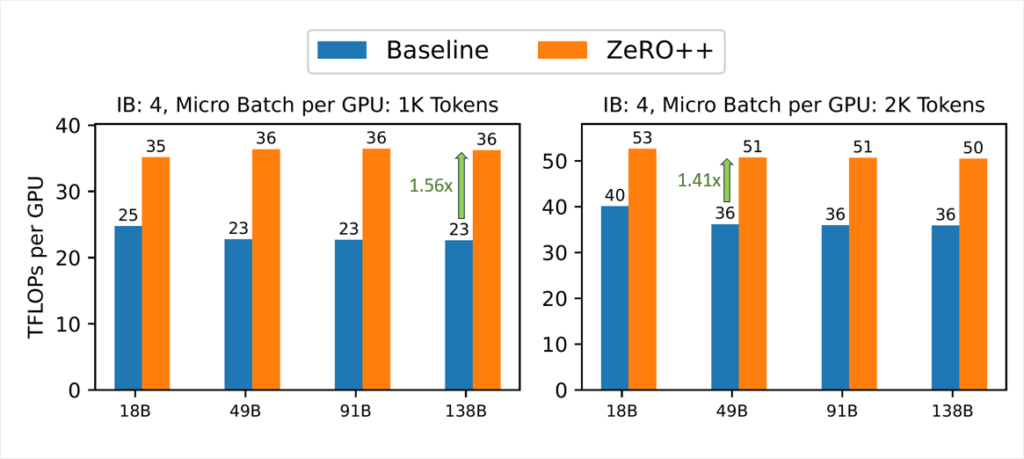
DeepSpeed ZeRO++: A leap in speed for LLM and chat model training with 4X less communication - Microsoft Research

Optimization approaches for Transformers [Part 2]

GitHub - microsoft/DeepSpeed: DeepSpeed is a deep learning optimization library that makes distributed training and inference easy, efficient, and effective.

Shaden Smith on LinkedIn: DeepSpeed Data Efficiency: A composable library that makes better use of…

PDF] DeepSpeed- Inference: Enabling Efficient Inference of Transformer Models at Unprecedented Scale

Amanuel Alambo (@amanuel_alambo) / X

Interpreting Models – Machine Learning
![]()
Jean-marc Mommessin, Author at MarkTechPost
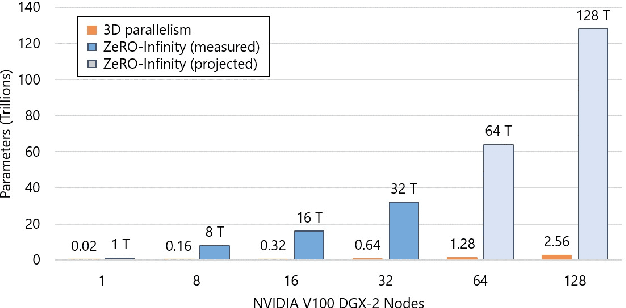
Jeff Rasley - CatalyzeX

Optimization approaches for Transformers [Part 2]
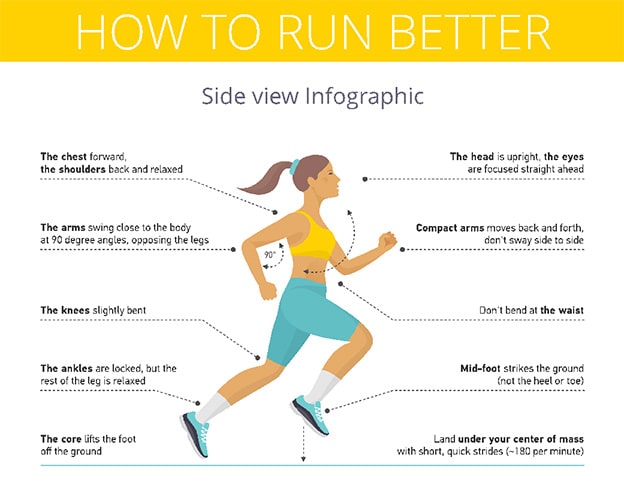








:max_bytes(150000):strip_icc()/murphy-compressed-252e13b55718412982ef031a965dbaff.png)