Search
Fine-Tuning Insights: Lessons from Experimenting with RedPajama
$ 11.50 · 4.8 (219) · In stock


media.licdn.com/dms/image/D4D22AQGvRrVCO6Dl0w/feed

OpenFlamingo v2: New Models and Enhanced Training Setup — Stability AI
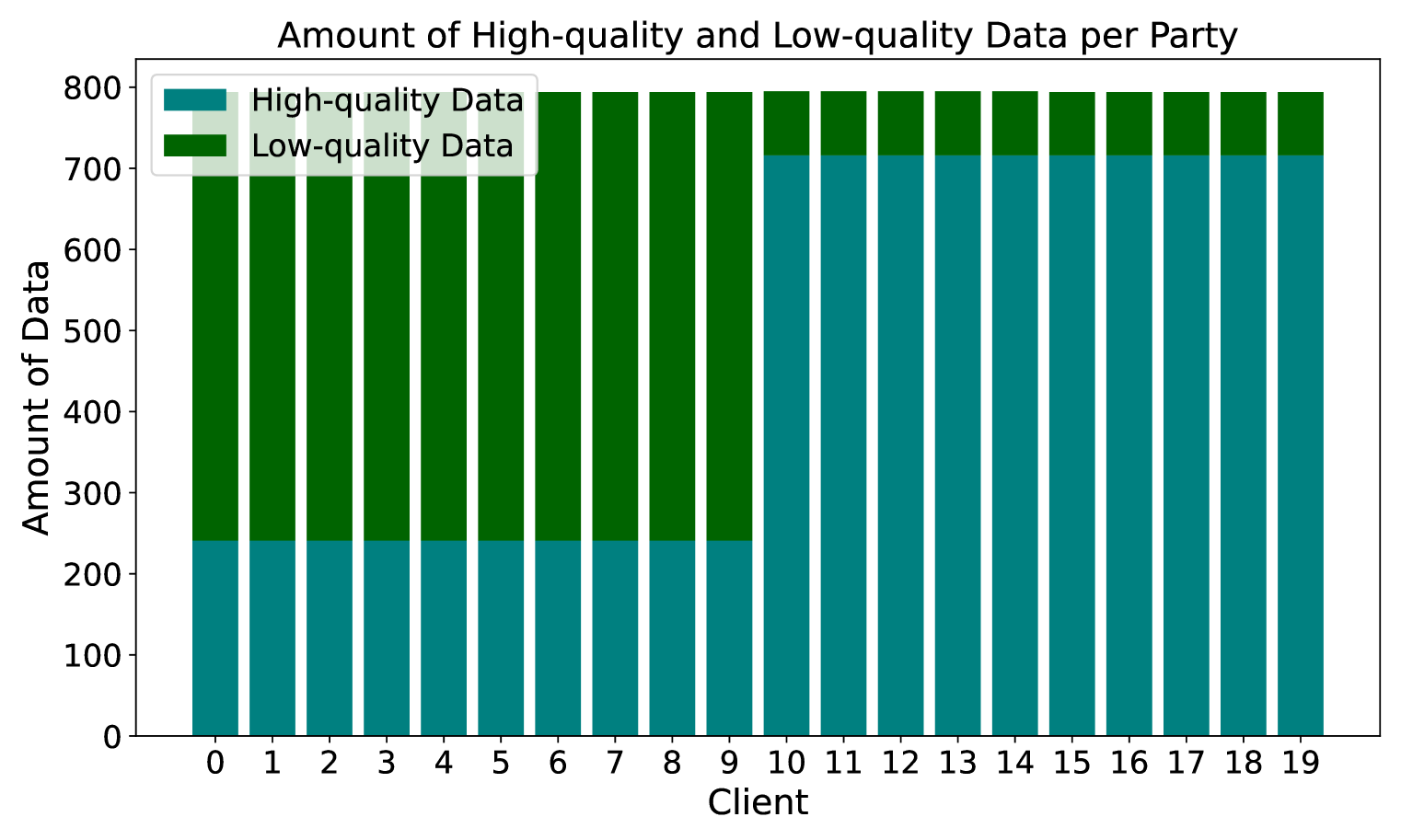
Enhancing Data Quality in Federated Fine-Tuning of Foundation Models
Union for AI Orchestration

RedPajama training progress at 440 billion tokens
Samhita Alla – Medium

RedPajama-INCITE-3B, an LLM for everyone
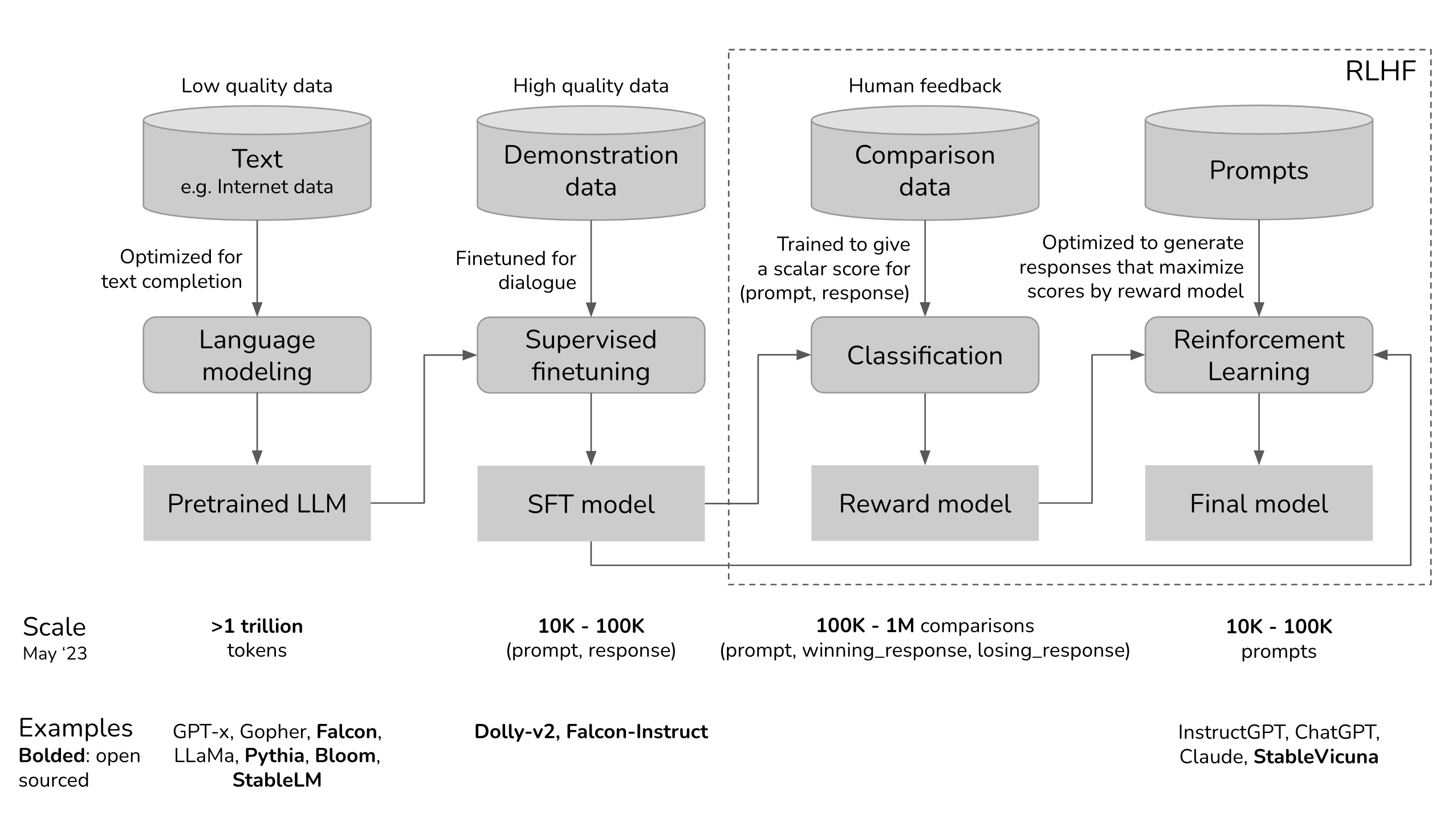
RLHF: Reinforcement Learning from Human Feedback

Create a Clone of Yourself With a Fine-tuned LLM, by Sergei Savvov

Esteve Graells on LinkedIn: #ai #structured #unstructured #ai #sql #asynchronously #user #experience…
You may also like





Related products




