Fine Tuning Is For Form, Not Facts
$ 16.00 · 5 (234) · In stock
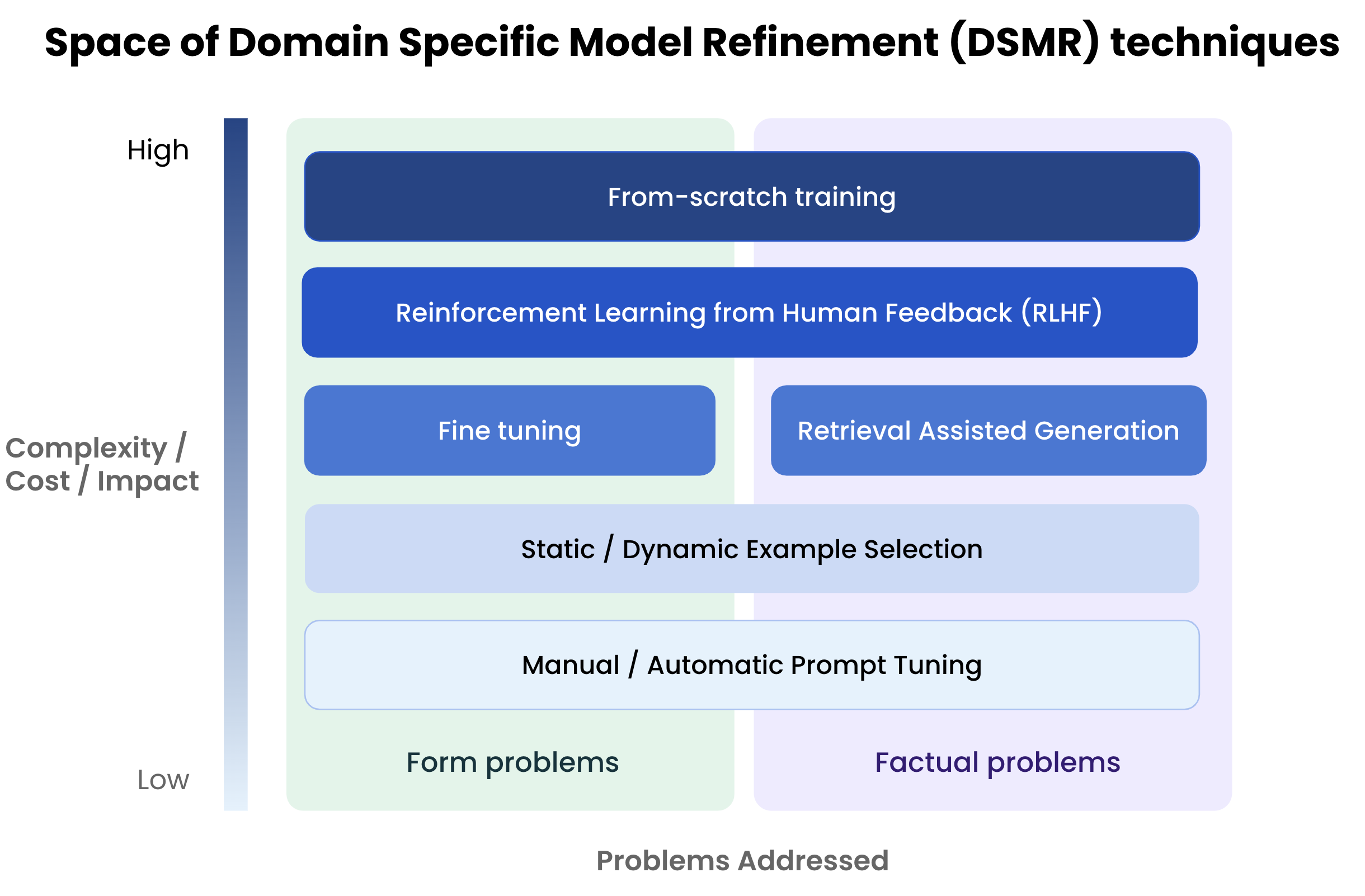
Fine tuning is one approach to domain-specific model refinement (DSMR), but it’s not a silver bullet for improving domain-specific performance.

Reinforcement Learning as a fine-tuning paradigm

Fine-Tuning LLMs: Overview, Methods & Best Practices

Use Case Patterns for LLM Applications (1).pdf
LLM Fine-Tuning: What Works and What Doesn't?, by Gao Dalie (高達烈)

Fine-tuning large language models (LLMs) in 2024
The Reversal Curse: Uncovering the Intriguing Limits of Language Models, by Synced, SyncedReview
An introduction to RAG and simple/ complex RAG, by Chia Jeng Yang, WhyHow.AI
そのタスク LLM? Fine-tuning?(論文:「Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond」) #AI - Qiita
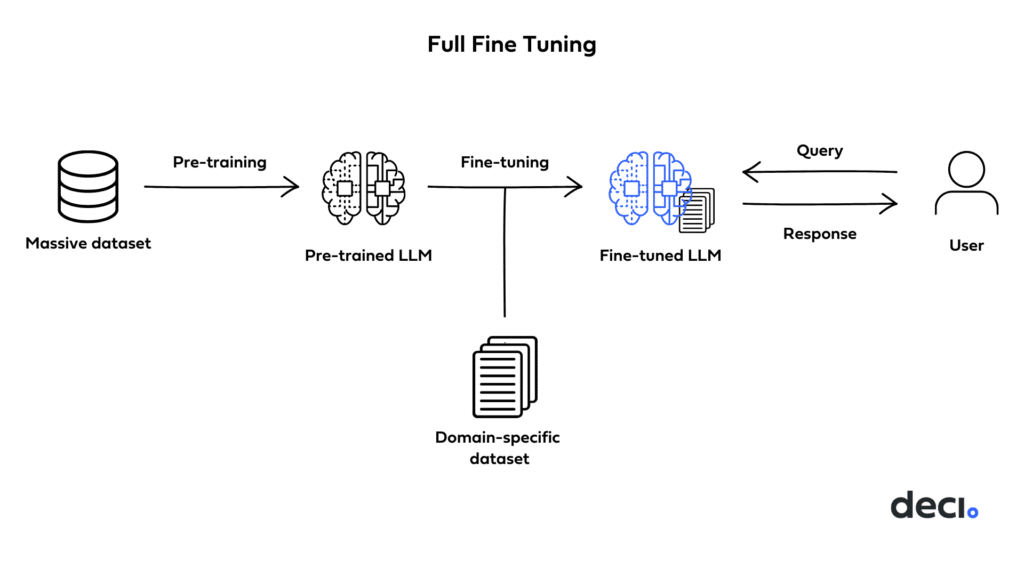
Full Fine-Tuning, PEFT, Prompt Engineering, or RAG?

General] Hawking on Fine-tuning : r/ChristianApologetics
Fine-Tuning Llama-2: A Comprehensive Case Study for Tailoring Models to Unique Applications - 西尾泰和のScrapbox
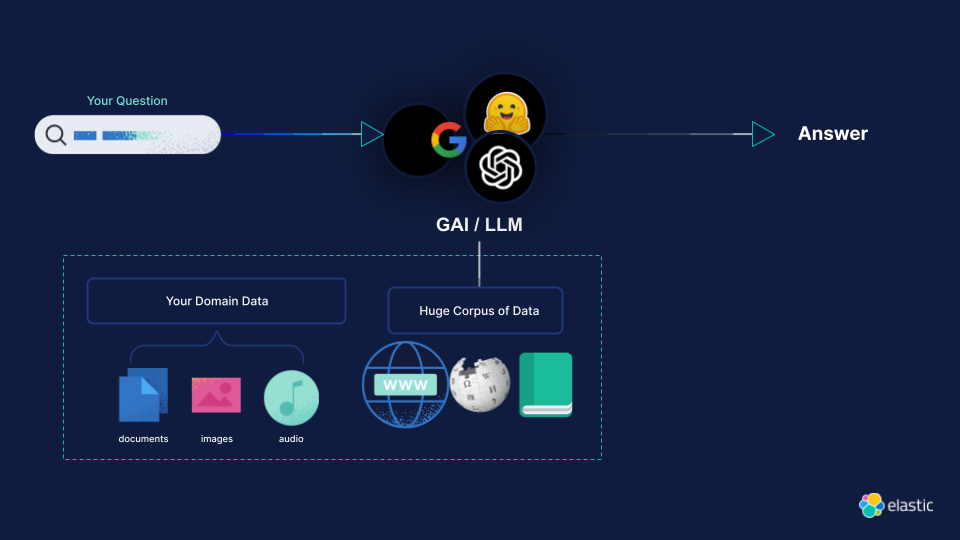
Domain Specific Generative AI: Pre-Training, Fine-Tuning, and RAG — Elastic Search Labs
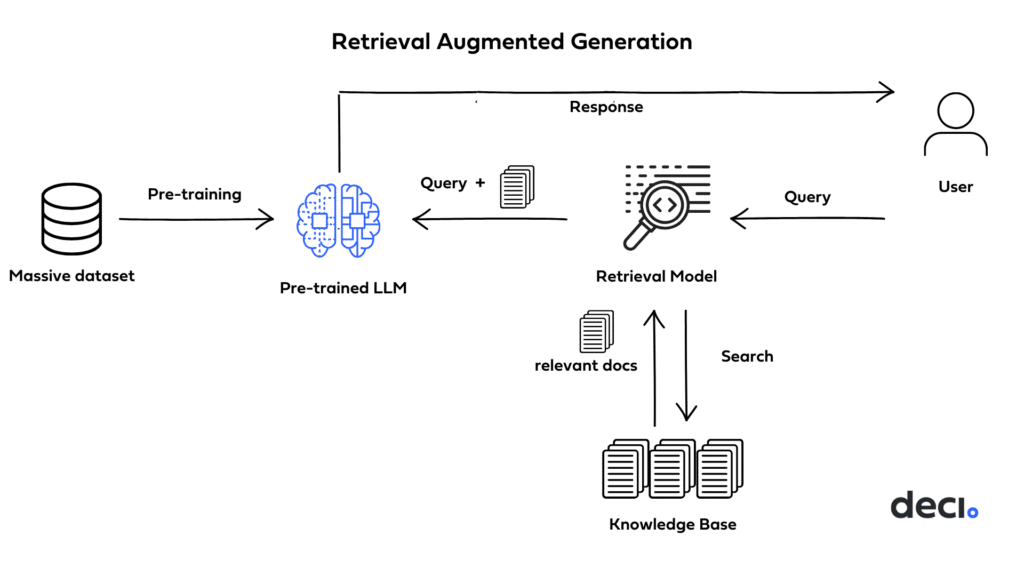
Full Fine-Tuning, PEFT, Prompt Engineering, or RAG?
An introduction to RAG and simple/ complex RAG, by Chia Jeng Yang, WhyHow.AI
![]()
LLMのファインチューニングで事実の学習ができないのは本当か?ちょっと実験してみた
:max_bytes(150000):strip_icc()/GettyImages-1442168521-4b95b8170c0d402f89e9b5082dcb6e33.jpg)








